

Osoittimet
Osoittimet ovat keskeinen osa C-ohjelmointia ja yleensä välttämättömiä melkeinpä missä tahansa C-ohjelmassa. Mahdollisuus viitata suoraan tietokoneen muistiin (käyttöjärjestelmän kautta) osoittimien avulla on yksi tärkeimmistä tekijöistä joka erottaa C:n monista muista, korkeamman abstraktiotason ohjelmointikielistä. Valitettavasti mahdollisuus käsitellä suoraan muistia antaa mahdollisuuden monenlaisiin virheisiin, jotka saattavat välillä olla hankalia löytää.
Taustaa
Ohjelmakoodissa esitelly muuttujat tarvitsevat muistia, jonka koko riippuu muuttujan tietotyypistä. Esimerkiksi char - tyyppinen muuttuja käyttää yhden tavun (8 bittiä), ja int - tyyppinen muuttuja yleensä neljä tavua (32 bittiä) koneen muistista. Järjestelmä varaa muuttujien tarvitseman tilan automaattisesti kun muuttuja esitellään, ja vapauttaa muuttujan käyttämän muistin, kun ohjelmalohkosta, jossa muuttuja esiteltiin, poistutaan. Ohjelmalohkon ulkopuolella tällaiseen muuttujaan ei enää siis voi viitata, eikä sitä voida käyttää. (Ohjelmalohkohan oli aaltosulkujen sisältämä alue ohjelmasta)
Esimerkiksi seuraava esimerkki
1 2 3 4 5 6 7 | void main(void) { char a = 10; char b = 12; int c = 123456; char *d = &a; } |
ei tee muuta kuin määrittelee neljä muuttujaa, ja varaa muistista tilaa seuraavasti:
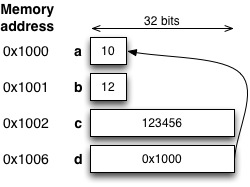
Muuttujat a ja b käyttävät yhden tavun koneen muistista, ja muuttuja c käyttää 4 tavua. Kyseinen ohjelma myös alustaa muuttujien sisällön annetuilla arvoilla (muutenhan niiden sisältö saattaisi olla mitä tahansa).
Muuttuja d onkin uuden tyyppinen muuttuja: se on osoitin joka viittaa johonkin kohtaan tietokoneen muistissa. Muuttujan määrittelyssä kerrotaan, että osoitin nimenomaisesti viittaa char - tyyppiseen muuttujaan jossain päin muistia. Muuttujan tunnistaa osoittimeksi siitä, että tyyppimäärittelyn perässä on tähtimerkki. Tähtimerkki on aina tietotyypin perässä, mutta sitä voi edeltää väli, tai sitten ei. Allekirjoittanut on tottunut ylläolevan kaltaiseen merkintätyyliin.
Vaikka d viittaa char - tyyppiseen arvoon, muuttuja käyttää koneen muistista enemmän tilaa kuin yhden tavun, koska muuttujaan tallennetaan muistiosoite, eikä arvoa välillä -127 - 127. Muistiosoitteet ovat kooltaan nykyisissä järjestelmissä usein 64 bittiä, mutta voivat olla myös 32 bittiä, kuten kuvan esimerkissä.
Osoittimet voivat toki viitata minkätyyppiseen muuttujaan tahansa (jopa toiseen osoitinmuuttujaan). On kuitenkin tärkeää, että viitattu tietotyyppi on oikein osoittimen esittelyn yhteydessä, sekä silloin kun sitä myöhemmin käytetään. Viittaaminen muistialueeseen, johon on talletettu toisentyyppisiä arvoja on teknisesti mahdollista, mutta aiheuttaa miltei aina väärää toimintaa. Kääntäjä varoittaa näistä, ja ne varoitukset on syytä ottaa tosissaan.
Myös muuttuja d alustetaan, (melkein) uuden näköisellä merkinnällä
&a. & - operaattori kertoo sitä seuraavan muuttujan sijainnin
muistissa. &a palauttaa siis muuttujan a muistiosoitteen, joka
voidaan sijoittaa osoitinmuuttujaan.
Kuvassa havainnollistuksen vuoksi on myös merkattu kuvitteellisia muistiosoitteita, joista näkee, että muuttujan d sisältö on niinikään muistiosoite. Normaalisti ohjelmoijan ei tarvitse tietää mitä yksittäiset osoitteet ovat, vaan mikä kunkin osoitinmuuttujan käyttötarkoitus on.
Käytöstä poistuneet muuttujat
Kuten mainittua, ohjelmalohkon loppuessa sen sisällä määritellyt muuttujat ja niiden varaama muisti vapautetaan. Käytännössä tämä tarkoittaa, että kyseinen muistialue voidaan ottaa muuhun käyttöön. Jos muualla ohjelmassa on edelleen osoitinmuuttujia, jotka viittaavat vapautettuun alueeseen, niiden sisältö pysyy ennallaan. Tällaisen osoittimen varomaton käyttö johtaa kuitenkin väärään lopputulokseen, koska viitatun muistialueen sisältö tulee muuttumaan järjestelmän ottaessa muistin johonkin muuhun käyttöön. Tämä on aloittelijoilla kohtuullisen yleinen, ja monesti hankalasti havaittava virhe, koska ohjelman käyttäytyminen näyttää tällöin vaihtelevan satunnaisesti.
Kuten muidenkin muuttujien kohdalla, alustamaton osoitinmuuttuja on sisällöltään määrittelemätön, ja osoittaa siis satunnaiseen paikkaan tietokoneen muistissa. Sellaisen muuttujan käyttö aiheuttaa melkein aina ohjelman keskeyttämisen virheelliseen muistiviittaukseen.
Käyttöjärjestelmä keskeyttää ohjelman "segmentation fault" - signaalilla, kun se huomaa että ohjelma yrittää käyttää muistia, jota sille ei ole alunperinkään varattu. Monesti kuitenkin virheellinen muistiviittaus osoittaa alueelle, jonka käyttöjärjestelmä on jo aiemmin antanut ohjelman käyttöön. Tällöin seurauksena on vain satunnaista väärää toimintaa. Tilanteen havaitsemiseksi on joitain työkaluja, joista kerrotaan myöhemmin.
Osoittimen käyttö
Osoittimen takaa löytyvä varsinainen sisältö haetaan
viittausoperaattorilla (*). Tämä operaattori kurkistaa siis
annetun osoittimen viittaamaan muistipaikkaan, ja palauttaa siellä
olevan arvon. Tämän arvon tyyppi vastaa osoittimen määrittelyn
yhteydessä annettua tietotyyppiä, mikäli osoitinta on käytetty
oikein. C:n kehittäjien valinta käyttää tähtioperaattoria viittaamiseen
voi herättää hämmennystä: sehän tarkoittaa myös
kertolaskua! Operaattorin kulloinenkin merkitys selviää kuitenkin
asiayhteydestä.
Toisaalla netissä: Miksi viittausoperaattori ja kerto-operaattori ovat samat?
Jatketaanpa äskeistä esimerkkiä muutamalla lisärivillä:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | int main(void) { char a = 10; char b = 12; int c = 123456; char *d = &a; char *e; e = d; printf("*e: %d e: %p\n", *e, e); *d = 13; printf("*d: %d d: %p *e: %d a: %d\n", *d, d, *e, a); if (*d > b) printf("New value is greater than b!\n"); } |
Osoitinmuuttujia käsitellään paljolti kuten muitakin muuttujia: sijoitus on mahdollinen, kuten rivillä 9 tehdään muuttujalle e. Tällöin muistiosoite kopioituu d:stä e:hen, ja molemmat muuttujat osoittavat sen jälkeen samaan paikkaan, eli muuttujan a sijaintiin.
Kuten mainittua, osoitinmuuttujan viittaaman muistin sisältö haetaan
viittausoperaattorilla. Siksi printf rivillä 10 tulostaa kaksi eri
asiaa: ensin osoitinmuuttujan takana lymyilevän arvon, ja toisekseen
osoitinmuuttujan itsensä arvon, eli jonkin muistiosoitteen. Tässä
opimme uuden muotoilumääreen printf:ää varten: %p olettaa
tulostavansa muistiosoitteen. Sitä ei kovin usein tarvita käytännössä,
mutta tässä esimerkissä se on kuitenkin käytössä. Huomaa kaksi
printf - parametria ja niiden ero: toinen on tähdellä ja toinen
ilman. Ne ovat kaksi eri arvoa.
Viittausoperaattoria voidaan käyttää myös silloin, kun osoitinmuuttujan viittaamaa muistialuetta halutaan muuttaa. Sekin käy sijoitusoperaattorilla, kunhan viittausoperaattoria käytetään asianmukaisesti. Viittausoperaattoria voi toisinsanoen käyttää osana lausekkeita erilaisissa tilanteissa, kuten muitakin operaattoreita: osana pidempiä laskutoimituksia, muuttujien parametreina, ja niin edelleen.
Rivillä 13 tulostamme useamman muuttujan arvon, jotta näemme mitä edeltävät rivit ovat saaneet aikaan. Seuraavaa näkyy:
*e: 10 e: 0x1000 *d: 13 d: 0x1000 *e: 13 a: 13 New value is greater than b!
main - funktion lopussa muistin sisältö näyttää tältä:
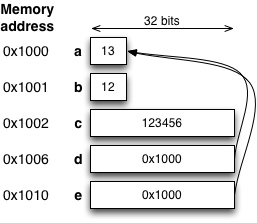
Osoitinmuuttujan välityksellä olemme siis muuttaneet myös muuttujan a sisältöä, johon nyt pääsee käsiksi sekä muuttujalla d, että muuttujalla e.
Jatketaanpa ohjelmaa edelleen, ja lisätään nyt rivejä jotka ovat virheellisiä:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | void main(void) { char a = 10; char b = 12; long int c = 123456; char *d = &a; *d = 13; printf("*d: %d d: %p a: %d\n", *d, d, a); if (*d > b) printf("New value is greater than b!\n"); d = 14; printf("d: %d\n", d); *d = 15; printf("bye bye!\n"); } |
Kun ohjelma käännetään, tuleekin varoituksia:
$ gcc -Wall -std=c99 -pedantic testi2.c testi2.c: In function ‘main’: testi2.c:12: warning: assignment makes pointer from integer without a cast testi2.c:13: warning: format ‘%d’ expects type ‘int’, but argument 2 has type ‘char *’
Riviä 12 koskeva varoitus kertoo, että sijoitusoperaattori yrittää
sijoittaa kokonaislukua osoitinmuuttujaan, mikä erittäin
todennäköisesti on väärin. Riviä 13 koskeva varoitus taas sanoo, että
yritämme käyttää %d - muotoilumäärettä osoitinmuuttujalle, mikä
erittäin todennäköisesti on väärin. Siitä huolimatta kääntäjä tuottaa
ajettavan ohjelman. Varoitukset kannattaa siis aina tarkistaa ja
poistaa ohjelmasta. Niin säästyy paljon omaakin aikaa.
Osoitinmuuttuja asettuu siis viittaamaan muistiosoitteeseen 14, mikä useimmissa järjestelmissä ei ole ohjelmien suorassa käytössä. Tämä ei sinänsä vielä kaada ohjelmaa, mutta kun kyseiseen osoitteeseen yritetään viitata rivillä 14, seuraavaa tapahtuu kun ohjelma ajetaan:
*d: 13 d: 1000 a: 13 d: 14 Segmentation fault: 11
Käyttöjärjestelmä keskeyttää ohjelman toiminnan kyseisessä kohdassa virheelliseen muistiviittaukseen. Numero 11 viittaa "Segmentation fault" - sigaalin tunnistenumeroon, eikä esimerkiksi ohjelman riviin. Käyttöjärjestelmä ei näkisikään ohjelman rivejä, koska ohjelma on ennen ajamista käännetty konekieliseksi. Lopputulos on kuitenkin se, että viimeistä "bye bye!" - tulostetta ei lainkaan tehdä.
Vaikka edellisessä esimerkissä unäärisiä * ja & - operaattoreita
on käytetty muuttujien yhteydessä, niitä voi käyttää lausekkeissa
muissakin yhteydessä. Esimerkiksi *(d + 2) viittaa
muistiosoitteeseen joka ei olekaan d:n sisältämä arvo, vaan hieman
tämän muistipaikan jälkeen. Tälle on paljon käyttöä, kuten pian nähdään.
- unäärinen operaattori: operaattori, joka liittyy yhteen
lausekkeeseen (operaattorin perässä) (esim:
*(a+1)on viittaus) - binäärinen operaattori: operaattori jota sovelletaan kahden
erillisen lausekkeen kanssa (esim:
(a+1) * (b+1)on kertolasku)
On myös hyvä huomata, että osoittimien yhteydessä *-merkkiä
käytetään kahdessa eri tarkoituksessa: kun muuttujaa määritellään
(esim. rivi 4), sillä merkitään erästä tietotyyppiä. Lausekkeiden
osana unäärisena operaattorina kyseessä on muistiviittaus. Ja lisäksi
on kertolaskun tapaus: *(a+1) * *(b+1) on myöskin validia C:tä,
jossa kerrotaan kaksi lukuarvoa jotka haetaan tiettyjen osoittimien
takaa.
Seuraavassa osoittimiin liittyvä välivideo (joka on tehty hyvän aikaa sitten Stanfordissa):

Osoittimet funktioissa
Osoittimia voi käyttää funktion parametreina tai paluuarvoina kuten
mitä tahansa muitakin tietotyyppejä. Olemme tietämättämme jo näin
tehneetkin sekä printf että scanf - funktioissa: printf -
funktioissa olemme käyttäneet merkkijonoja, joita C:ssä käytetään
osoittimien kautta. scanf - muuttujan yhteydessä parametriksi ollaan
annettu muuttujan osoite unääristä & - operaattoria käyttäen, eikä
varsinaista muuttujaa. Kohta kenties valkenee, miksi scanf:n
yhteydessä näin piti tehdä.
Seuraavassa on esimerkkinä my_readint - funktio, joka lukee yhden ASCII-merkin käyttäjältä, ja muuntaa sen kokonaisluvuksi. Saman asian voi tehdä useammallakin muulla C-kirjaston funktiolla helpomminkin, mutta toimikoon tämä nyt esimerkkinä. Funktio ei palautakaan luettua lukuarvoa paluuarvonaan, vaan se kirjoitetaan suoraan parametrina annettuun osoitteeseen. Paluuarvoksi tulee sen sijaan 1, jos numeron luku onnistui, tai 0, jos käyttäjä esimerkiksi antoi jonkin muun merkin kuin numeron.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | #include <stdio.h> int my_readint(int *value) { char c; int ret; ret = scanf("%c", &c); // luetaan yksi ASCII-merkki if (ret == 1 && c >= '0' && c <= '9') { int num = c - '0'; // muutetaan vastaavaksi luvuksi *value = num; // kirjoitetaan osoittimen näyttämään paikkaan return 1; } return 0; } int main(void) { int a; int *ptr_a = &a; if (my_readint(ptr_a)) printf("reading succeeded: %d\n", a); // Toinen tapa samalle asialle my_readint(&a); } |
Edellä olevassa ohjelmassa on paljonkin hyödyntöntä koodia: olisimme
esimerkiksi voineet kutsua vain scanf("%d", value). Tarkoitus oli
kuitenkin näyttää ensinnäkin se, että osoitintyypit toimivat
funktioissa kuten muutkin tyypit, ja että kutsuttaessa pitää tiedostaa
että käytetään osoitinta eikä perustietotyyppiä, ja tarvittaessa
käyttää osoiteoperaattoria (&) jotta saadaan käyttöön toimiva
osoitin. Lisäksi nähdään yksi hankala tapa muuntaa ASCII-muotoisia
lukuarvoja vastaavaksi kokonaisluvuksi välillä 0-9. Miksi muuten
scanf("%d", value) ei tarvitsekaan & - operaattoria, kuten aiemmin
nähtiin?
scanf - funktio toimii samalla periaatteella: luettava arvo ei palaudukaan paluuarvona, vaan parametrina olevan osoittimen välityksellä. Osoittimien avulla funktiot pääsevät siis käsittelemään muistialueita ja toisia muuttujia, joita ei ole määritelty funktion sisällä. Samalla funktion paluuarvo vapautuu muuhun käyttöön, esimerkiksi sen kertomiseen, onnistuiko funktio vai ei.
Osoitin voi toimia myös funktion paluuarvona. Tällöin return - lauseessa annetavan lausekkeen on myös oltava osoitin. Seuraavassa on esimerkki, joka lukee scanf:ää käyttäen kokonaisluvun käyttäjältä. Kokonaisluku tallennetaan muistiin osoitinmuuttujan number viittaamaan paikkaan. Kokonaisluvun lukemisen onnistuessa, funktio palauttaa parametrinä saaneensa osoittimen.
Osoittimen arvoa NULL käytetään ilmaisemaan erikoistapauksia kuten virheitä ja sitä, että osoitin ei ole käytössä. NULL ei ole osa C:n syntaksia, vaan se on vakio, joka on määritelty otsaketiedostossa stddef.h.
Esimerkin funktio palauttaa NULL - arvoisen osoittimen, mikäli kokonaisluvun lukeminen epäonnistui. Mikäli annetun osoittimen arvo on NULL, ei siihen voida kirjoittaa kokonaislukua ja tällöin scanf - kutsu keskeyttäisi ohjelman virheellisen muistiviittauksen takia. Myös scanf - kutsu voi epäonnistua, esimerkiksi virheellisen syötteen takia. Kummassakin tapauksessa virheestä kerrotaan funktiota kutsuneelle koodille palauttamalla NULL - arvoinen osoitin.
1 2 3 4 5 6 7 8 9 10 11 12 | int *read_int(int *number) { int ret; if (number == NULL) { // Tarkistetaan annetu osoitin return NULL; // Osoittimen ollessa epäkelpo, funktiosta poistutaan } ret = scanf("%d", number); if (ret != 1) { // Tarkistetaan onnistuiko lukeminen return NULL; } return number; } |
Task 02_basics_1: Numeroiden vaihto (1 pts)
Tavoite: Ensikosketus osoittimien käyttöön.
Toteuta funktio number_swap(int *a, int *b) joka saa kaksi
int-osoitinta parametrikseen. Funktion tulee vaihtaa osoittimien
päässä olevat arvot keskenään. Esimerkiksi seuraavassa koodissa
val1:n sisällöksi pitäisi tulla 5 ja val2:n sisällöksi 4.
1 2 3 4 5 | int val1 = 4; int val2 = 5; number_swap(&val1, &val2); if (val1 == 5 && val2 == 4) { printf("Great, it worked!\n"); } |
Osoitearitmetiikka
Plus- ja miinuslaskuja voi soveltaa myös osoittimiin. Tällöin osoitin siirtyy eteen- tai taaksepäin annetun määrän "askelia". Askeleen koko tavuissa laskettuna riippuu tietotyypistä, johon osoitin osoittaa. Käytännössä tämän mekanismin avulla voidaan käydä läpi taulukoita, eli muistissa olevia saman tietotyypin alkioista koostuvia lukujonoja.
Alla oleva esimerkki pyrkii valottamaan osoitearitmetiikan toimintaa. Siinä viitataan samalla hieman etuajassa jo taulukkotietotyyppiin, josta asiaa hetken päästä.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <stdio.h> int main(void) { int array[50]; // varaa tilaa 50 peräkkäiselle kokonaisluvulle int *intPtr = array; // aseta osoitin osoittamaan taulukon alkuun int i = 50; while (i > 0) { *intPtr = i * 2; // kirjoitetaan i*2 osoittimen viittaamaan paikkaan intPtr++; // siirretään osoitin seuraavan alkion kohdalle i--; } intPtr = array; // siirretään intPtr-osoitin takaisin alkuun for (i = 0; i < 50; i++) { int value = *(intPtr + i); // haetaan taulukosta i:s alkio printf("%d ", value); } } |
Kun funktio on varannut tilan 50:lle kokonaisluvulle, se esittelee
osoitinmuuttujan intPtr, joka osoittaa taulukon alkuun. Kuten
riviltä 6 huomataan, osoittimen voi asettaa viittaamaan talukon alkuun
helposti. While-silmukkaa toistetaan 50 kertaa, käyttäen apuna
i-muuttujaa, joka pienenee joka kierroksella. Jokaisella
kierroksella käydään sijoittamassa taulukkoon tietty kokonaisluku (i *
2), jonka jälkeen osoitin siirretään seuraavaan kohtaan taulukossa
"lisää yksi"-operaation avulla.
Rivillä 14 osoitinmuuttuja siirretään osoittamaan takaisin taulukon alkuun, koska muuten se osoittaisi yli taulukon lopun, ja sen käyttö johtaisi virheelliseen toimintaan.
Lopuksi käydään läpi kaikki taulukon 50 alkiota ja tulostetaan ne ruudulle. Rivillä 17 nähdään, kuinka osoitinmuuttuja toimii lausekkeessa: ensin etsitään i:s alkio osoittimesta intPtr laskettuna, ja viitataan siihen viittausoperaattorilla, jolloin saadaan tulokseksi tavallinen kokonaisluku -- siis se, joka käytiin hetki sitten sijoittamassa taulukkoon. Sulkeiden käyttö on tärkeää, koska muuten kääntäjä arvioisi viittausoperaattorin ennen yhteenlaskua, mikä johtaisi väärään lopputulokseen. Operaattoreiden laskujärjestyksestä lisää asiaa hetken kuluttua.
Toisin sanoen funktio tulostaa lopussa parilliset luvut 100:sta 2:een.
Jotta osoitearitmetiikka voisi toimia oikein, on tärkeää että osoittimen tietotyyppi vastaa taulukossa olevien alkioiden tietotyyppiä. Kääntäjä pitää yleensä tästä huolen, ja varoittaa virheellisestä käytöstä.
Osoittimia voi käyttää myös vertailuoperaatioissa, jolloin on hyvä huomata että tällöin verrataan muistiosoitteita, eikä niitä lukuarvoja joihin muistiosoitteet viittaavat. Esimerkiksi seurava ohjelmanpätkä kertoo että annetut kaksi osoitinta eroavat toisistaan, mutta niiden osoittamat kokonaislukuarvot ovat yhtä suuria.
1 2 3 4 5 6 7 8 9 10 11 12 | int a = 5; int b = 5; int *pa = &a; int *pb = &b; if (pa == pb) printf("Pointers are same\n"); else printf("Pointers are different\n"); if (*pa == *pb) printf("Values are same\n"); |
Task 02_basics_2: Taulukkosumma (1 pts)
Tavoite: Harjoittele taulukon käyttöä
Toteuta funktio int array_sum(int *array, int count), joka laskee
taulukon array alkioiden summan ja palauttaa sen
paluuarvonaan. Taulukossa olevien numeroiden määrä kerrotaan
parametrilla count.
Esimerkiksi seuraavan ohjelman tulisi asettaa ret 1110:ksi.
1 2 | int valarray[] = { 10, 100, 1000 }; int ret = array_sum(valarray, 3); |
Taulukot
Perusteet
Taulukko on jono tietyn tyyppisiä arvoja, jotka sijaitsevat peräkkäisissä muistipaikoissa. Kun taulukkomuuttuja esitellään, sen koko annetaan, jotta C-kääntäjä osaa varata sille riittäävän määrän muistia. C:ssä taulukon koko ilmaistaan hakasulkeiden sisällä.
Alla on esimerkki taulukosta (muuttujassa slots):
1 2 3 4 5 6 7 8 9 10 11 12 | short apples = 10; short slots[4]; short oranges = 20; int i; for (i = 0; i < 4; i++) { /* Alustetaan taulukko lukuarvoilla */ slots[i] = i + 1; } for (i = 0; i < 4; i++) { /* Tulostetaan taulukossa olevat luvut */ printf("array element %d is %d\n", i, *(slots + i)); } |
Ohjelmassa on kolme muuttujaa: apples ja oranges ovat tavallisia lyhyitä kokonaislukuja, mutta slots on taulukko johon mahtuu neljä short - tyyppistä lukua. Kuten muidenkin C:n muuttujien kanssa, taulukon sisältöä ei ole määritelty, ennenkuin alkioihin on sijoitettu jotkin arvot. Taulukon sisältö ei välttämättä ole täynnä nollia, kuten joissain muissa ohjelmointikielissä, vaan luvut voivat olla näennäisesti täysin satunnaisia. Edellä oleva ohjelma asettuu muistiin seuraavalla tavalla:
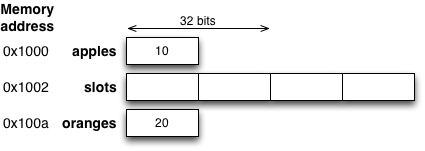
Taulukon vaatima tila riippuu tietotyypistä ja alkioiden lukumäärästä: koska short - tyyppi on 16 bittiä, eli 2 tavua, koko taulukko vie muistista 8 tavua.
Rivillä 6 alkaa silmukka, jossa taulukon alkiot alustetaan. Taulukon
alkioita indeksoidaan käyttämällä hakasulkeita. Hakasulkeiden sisällä
on tässä tapauksessa i-muuttuja, mutta ne voivat sisältää minkä
tahansa monimutkaisemmankin lausekkeen. Ensimmäisen alkion indeksi on
0, eli tässä tapauksessa viimeisen alkion saisi kutsumalla slots[3].
Taulukoilla ja osoittimilla on läheinen suhde. slots - muuttujaa voi
käyttää kuten osoitinta, ja sen voi sijoittaa short * - tyyppiseen
muuttujaan, tai käyttää vastaavantyyppisessä
funktioparametrissa. Tällöin osoitin viittaa taulukon ensimmäiseen
alkioon. Muihin taulukon alkioihin pääsee käsiksi siirtämällä
osoitinta halutun määrän eteenpäin normaaleilla osoitinaritmeettisilla
laskutoimituksilla. Tästä esimerkki rivillä 11. Monesti helpompi (ja
kauniimman näköinen) tapa on käyttää kuitenkin indeksioperaattoria,
eli slots[i]. Tämä onkin oikeastaan vaan nätimpi esitysmuoto yllä
olevan näköiselle laskutoimitukselle, ja tekee täsmälleen saman
asian. Yllä oleva ohjelma tulostaa siis seuraavaa:
array element 0 is 1 array element 1 is 2 array element 2 is 3 array element 3 is 4
C-kääntäjä ei tarkista indeksoidaanko taulukkoa oikein, ja yleinen virhe indeksoida taulukko yli sen varaaman muistialueen. Jos tämä tehdään taulukkoon kirjoittaessa, ohjelma käy muokkaamassa väärää kohtaa muistista, koska taulukkoon indeksoiminenhan vastaa viittausta muistipaikkaan, joka esitetään indeksin ja taulukon alkuosoitteen avulla. Esimerkiksi seuraava ohjelma kääntyy, mutta toimii virheellisesti (käymällä läpi kuusi alkiota taulukon alusta):
1 2 3 4 5 6 7 8 9 10 11 12 | short apples = 10; short slots[4]; short oranges = 20; int i; for (i = 0; i < 6; i++) { /* Here we initialize the array */ slots[i] = i + 1; } for (i = 0; i < 6; i++) { /* Output the values in array */ printf("array element %d is %d\n", i, *(slots + i)); } |
Käytännössä tuloksena apples tai oranges muuttujan arvo saattaa muuttua, koska ne sijaitsevat muistipaikoissa jotka ovat lähellä slots - taulukkoa. Tarkka käyttäytyminen vaihtelee eri alustojen ja kääntäjien mukaan, riippuen siitä miten kääntäjä sijoittaa muuttujat muistiin. Tällaiset virheet eivät ole harvinaisia, ja monet tietoturva-aukot perustuvat virheisiin, jotka liittyvät taulukon "yli" kirjoittamiseen, ja muistin manipulointiin sen avulla. Pari vuotta sitten puhuttiin esimerkiksi Heartbleed - tietoturva-aukosta, joka perustui samantapaiseen ohjelmointivirheeseen.
Kuten muidenkin tyyppisten muuttujien kohdalla, myös taulukko voidaan alustaa samalla kun se esitellään. Tässä pari tapaa tehdä asia:
1 2 | short slots[5] = { 3, 7, 2, 123, 45 }; int numbers[] = { 67, 12, 34 }; |
Tästä nähdään, että silloin kun taulukko alustetaan, sen kokoa ei tarvitse erikseen kertoa, koska kääntäjä päättelee sen alustuksessa olevien arvojen määrästä. Tällöin kuitenkin määrittelyn yhteydessä pitää silti olla hakasulut, jotta tiedetään tyypin olevan taulukko. Mikäli alustuslista on lyhyempi kuin hakasulkeissa annettu koko, loput alkiot alustuvat nollilla. Helppo tapa alustaa isokin taulukko nolliksi, on siis tehdä esimerkiksi näin:
int taulu[1000] = { 0 };
Taulukot funktioiden yhteydessä
Taulukko voidaan antaa funktion parametrina, mutta tällöin tietotyyppi määritellään usein osoittimena, koska taulukkotyyppinen muuttuja muuttuu automaattisesti osoittimeksi. Tällaisesta parametrista ei kuitenkaan näe taulukon kokoa, vaan taulukon koko pitää välittää funktiolle jollain muulla tavoin. Seuraavassa muutama tapa tehdä tämä:
- Funktiolla on toinen parametri, jossa taulukon koko kerrotaan (esim. main-funktion versio, jossa annetaan ohjelman komentoriviparametrit)
- Taulukko loppuu johonkin määriteltyyn erikoisarvoon (esimerkiksi 0:aan, kuten C:n merkkijonojen tapauksessa)
- Jos taulukko on kokonaislukumuotoinen, sen koko voidaan kertoa ensimmäisessä alkiossa (tietoliikenneprotokollat suunnitellaan monesti näin)
- jne...
Mikäli taulukon koko ilmoitetaan osana taulukkorakennetta, täytyy muistaa taulukkoa esitellessä varata tilaa myös tälle "ylimääräiselle" alkiolle. C:ssä ei ole mitään sisäänrakennettua mekanismia kysyä taulukon kokoa ohjelman ajon aikana, kuten esimerkiksi Pythonissa tai Javassa, vaan ohjelmoijan täytyy pitää asiasta kirjaa osana ohjelmaa, esimerkiksi erillisessä muuttujassa.
Taulukkoa ei voi palauttaa funktion paluuarvona. Mikäli funktion tarvitsee välittää taulukko sen kutsuneelle ohjelmalle, taulukko pitää varata funktion ulkopuolella etukäteen, tai funktion pitää varata taulukolle muisti dynaamisesti (käsitellään modulissa 3).
Tässä esimerkki, kuinka taulukkoa käytetään funktiossa. Siinä siis käytetään muuttujaa n ilmaisemaan taulukon a koko. Ohjelmassa esiintyy myös sizeof - määre, jonka avulla voidaan kysyä tietotyypin vaatimaa tilaa tavuina. Tietyissä tapauksissa (kuten tässä rivillä 26) tätä mekanismia voidaan käyttää taulukon alkoiden määrän selvittämiseen (jaetaan taulukon koko yksittäisen tietotyypin koolla), mutta tämä tapahtuu käännösaikana. Kääntäjä siis korvaa sizeof - määreen kokonaisluvulla, joka vastaa kokoa.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | void show_table(short *a, size_t n) { int i; for (i = 0; i < n; i++) { // print the table using pointer arithmetics: printf("%d ", *(a + i)) // Also this would produce same result: printf("%d ", a[i]) // We could also do this for same effect, but pointer 'a' is modified. // Therefore, this cannot be used together with indexing, as above. // Modification of pointer 'a' is not visible outside the function. //printf("%d ", *a++); } printf("\n"); } int main() { short table[] = { 1, 4, 6, 8}; printf("size: %lu\n", sizeof(table)); /* print array size for fun */ /* below is one way to get the number of elements */ // sizeof(table) is 4 * sizeof(short) == 8; show_table(table, sizeof(table)/sizeof(short)); // in this case the above would be equivalent to: show_table(table, 4); } |
Task 02_basics_3: Taulukon lukija (1 pts)
Tavoite: Lisäharjoittelua taulukon käytöstä yhdessä scanf:n kanssa.
Toteuta funktio int array_reader(int *vals, int n) joka lukee
käyttäjältä kokonaislukuja vals-muuttujan osoittamaan
taulukkoon. Taulukon tarvitsema tila on jo valmiiksi varattu, ja
parametri n kertoo taulukon maksimikoon. Numerot voi lukea
scanf-funktiota käyttäen siten että niiden välissä on rivivaihto tai
väli, tai mikä tahansa ns. whitespace-merkki, joka toimii
oletusarvoisesti scanf-syötteen erottimena.
Mikäli käyttäjä ei syötä numeroa (mikä nähdään scanf-paluuarvosta), taulukko ja funktion suoritus loppuu. Funktion tulee palauttaa taulukon lopullinen koko, joka siis voi olla pienempi kuin n, mutta ei koskaan suurempi.
Alla esimerkki siitä kuinka funktiota voi testata:
1 2 3 4 5 6 7 | int array[10]; int n = array_reader(array, 10); printf("%d numbers read\n", n); int i; for (i = 0; i < n; i++) { printf("%d ", array[i]); } |
Esimerkiksi seuraava syöte lukee taulukkoon neljä numeroa, ja lopettaa sen jälkeen, kun viides arvo on viivamerkki.
5 8 2 7 -
Task 03_mastermind: Mastermind (1 pts)
Tavoite: Lisää harjoitusta taulukkojen käsittelystä.
Toteuta funktio void mastermind(const int *solution, const int
*guess, char *result, unsigned int len) joka vertaa
kokonaislukutaulukkoa guess taulukkoon solution. Molemmat taulukot
sisältävät len kokonaislukua välillä 0 ja 9. Funktio tuottaa
merkkitaulukon result, jossa on niin ikään len merkkiä
seuraavaasti:
-
Jos taulukoissa solution ja guess on sama numero N:nnessä taulukon paikassa, kyseinen paikka result - taulukossa merkataan '+' - merkillä.
-
Jos taulukossa guess on sellainen numero N:nnessä paikassa, joka sijaitsee jossain toisessa kohdassa solution - taulukossa, kyseinen paikka result - taulukossa asetetaan merkiksi '*'.
-
Jos N:s paikka taulukossa guess sisältää numeron, jota ei esiinny lainkaan taulukossa solution, kyseinen paikka result - taulukossa merkataan merkillä '-'.
Huomaa että taulukkoja solution ja guess ei kuulu muokata funktiossa, kun taas taulukko result on sellainen jonka funktio kirjoittaa.
Esimerkiksi kun len on 6, solution on { 2, 6, 6, 3, 5, 3} ja guess on {4, 5, 6, 1, 8, 9}, funktio asettaa result taulun sisältämään arvot {'-', '*', '+', '-', '-', '-'}.
main-funktio tiedostossa main.c toteuttaa yksinkertaisen Mastermind-pelin, jolla voi testata toteutustasi.
Task 04_sort: Järjestely (1 pts)
Tavoite: Lisää taulukkoharjoittelua, tällä kertaa alkoiden järjestelyä.
Toteuta funktio void sort(int *start, int size) joka järjestää
annetussa taulukossa (start) olevat kokonaisluvut nousevaan
suuruusjärjestykseen (pienimmästä suurimpaan). Voit käyttää
esimerkiksi valintalajittelua (selection sort): aloita etsimällä
taulukon pienin alkio, ja vaihda sen paikkaa taulukon ensimmäisen
alkion kanssa. Sitten tarkastelen lopputaulukkoa toisesta alkiosta
eteenpäin, ja jälleen vaihdan lopputaulukon pienimmän alkion taulukon
toisen alkion kanssa. Näin jatkat kolmanteen ja neljänteen alkioon,
kunnes koko taulukko on käyty läpi, jolloin taulukon alkiot ovay
oikeassa järjestyksessä. Testaa funktiota erilaisilla ja erikokoisilla
kokonaislukutaulukoilla,
Merkkijonot
Perusteet
C-kielessä ei ole sisäänrakennettua merkkijonotyyppiä, vaan merkkijonot esitetään char-tyyppisinä taulukkoina. Tällaisen char-taulukon viimeinen alkio on aina 0-merkki, josta merkkijonoa käyttävät funktiot tunnistavat merkkijonon lopun. 0-merkillä tarkoitetaan merkkiä, jonka ASCII-koodi on 0, ei siis numeroa esittävää merkkiä '0', jonka ASCII-koodi on jotain muuta. 0-merkki voidaan esittää merkkijonovakiona '\0'. 0-merkki ei näy ohjelman käyttäjälle, mutta vie kuitenkin yhden tavun merkkijonoa esittävästä char-taulukosta.
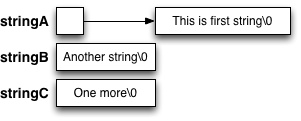
C-kieli sallii kuitenkin merkkijonojen (eli char-taulukoiden) esittämien lainausmerkkien sisällä, kuten esimerkiksi string_A:n ja string_B:n tapauksessa alla:
1 2 3 | char *string_A = "This is first string"; char string_B[] = "Another string"; char string_C[] = { 'O','n','e',' ','m','o','r','e','\0' }; |
Kun merkkijono esitetään lainausmerkkien sisällä yllä esitettyyn tapaan, kääntäjä lisää loppuun automaattisesti 0-merkin. On tärkeä huomioida, että kahden hipsun merkkijono ja yksinkertaisella hipsulla esitettävä merkkivakio ovat kaksi eri asiaa, toisin kuin joissain muissa ohjelmointikielissä.
Merkkijonot voi myös määritellä taulukkona merkki vakioita, kuten string_C:n yhteydessä tehdään. Tämä ei ole kovin kaunista tai yleistä, mutta havainnollistaa miten merkkijono on rakennettu. Tällöin ohjelmoijan pitää lisätä itse loppuun nollamerkki.
string_A ja string_B poikkeavat toisistaan siinä että string_B:n vaatima tila varataan funktiosta paikallisesti, ja kyseisen merkkijonon sisältöä voi muokata esimerkiksi normaaleja taulukko-operaatioita käyttäen. Sama pätee string_C:henkin. string_A on sen sijaan varattu toisesta muistin lohkosta, jota ei voi muokata, vaan sen sisältöä voi pelkästään lukea. Mikäli tällaista merkkijonoa yritetään muokata, ohjelman suoritus keskeytyy muistivirheeseen. Olisikin hyvä käyttää string_A:n määrittelyn yhteydessä const - määrettä, jolloin kääntäjä estää tällaiset yritykset jo käännösaikana. Myöskin string_B varaa paikallisesti tilaa koko merkkijonon tarvitseman määrän, kun taas string_A tarvitsee pelkästään muistiosoitteen vaatiman tilan, koska se on osoitin.
Alla olevassa kuvassa asiaa on havainnollistettu:
Merkkijonoja voi sisällyttää printf - tulosteisiin käyttämällä
%s - muotoilumäärettä. Myös tämän yhteydessä voi tarvittaessa
määritellä kentän leveyden ja muita parametreja, kuten aiemmin on
nähty. Alla printf - esimerkki:
1 2 | char string_B[] = "another string"; printf("My string is %s\n", string_B) |
Funktioissa merkkijonot esitetään yleensä char-osoittimien avulla, kuten taulukoiden kanssa yleisestikin tehdään. Esimerkiksi seuraava ohjelma "kryptaa" annetun merkkijonon kasvattamalla merkkikoodin sisältöä yhdellä (esimerkiksi 'A':sta tulee 'B', jne.)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | void encode(char *str) { while (*str) { // Lopettaa kun tullaan \0 - merkkiin *str = *str + 1; // muuta osoittimen osoittamaa merkkiä str++; // siirry seuraavan merkin kohdalle } } int main() { char message[] = "It is going to rain tomorrow"; encode(message); printf("encoded: %s\n", message); } |
encode - funktiossa nähdään myös tyypillinen esimerkki siitä miten merkkijono käydään läpi: while - silmukassa toistetaan haluttua toiminnallisuutta, ja joka kierroksella lisätään str - osoittimen arvoa yhdellä, eli se siirtyy seuraavan merkin kohdalle. Kun tullaan sellaisen merkin kohdalle joka on 0 (eli sen totuusarvo on epätosi), silmukasta poistutaan.
Merkkijonoa ei voi kopioida suoralla sijoitusoperaatiolla. Sen sijaan merkkijono pitää kopioida merkki kerrallaan uuteen paikkaan muistissa. Tähän on olemassa valmis funktio strcpy, vaikka kopiointi on helppo tehdä itsekin osoittimien avulla.
Task 06_strbasic_1: Laske aakkoset (1 pts)
Tavoite: Ensituntuman hankkiminen merkkijonoihin.
Kirjoita funktio int count_alpha(const char *str) joka laskee
aakkoskirjainten määrän annetussa merkkijonossa (str). Voit käyttää
hyväksesi funktiota int
isalpha(int character), joka
on määritelty
Hyödyllisiä määreitä ja operaattoreita
C-kielen määre voidaan antaa esimerkiksi muuttujan esittelyn yhteydessä, kun halutaan tarkentaa muuttujan käyttötarkoitusta. Operaattoreita olemme jo nähneetkin erilaisten laskutoimitusten yhteydessä, mutta C-kieli tarjoaa muunkinlaisia operaattoreita, esimerkiksi muuttujan koon ilmaisemiseen. Näitä voidaan käyttää lausekkeissa kuten mitä tahansa muitakin operaattoreita.
Tietotyypin koon selvittäminen
sizeof - operaattori kertoo annetun tietotyypin tai muuttujan koon. Koska monien C:n perustietotyyppien tarkkaa kokoa ei ole standardoitu, ohjelmakoodissa ei saa olettaa, että esimerkiksi int - tyyppinen muuttuja vaatisi muistia aina neljä tavua. Varsinkin rakenteisten tietotyyppien kohdalla (modulissa 3), tietotyypin varsinaisessa koossa voi olla useinkin allaolevasta järjestelmästä riippuvaa vaihtelua.
1 2 3 4 5 | short a; short *pa; printf("size a: %lu\n", sizeof(a)); printf("size *pa: %lu\n", sizeof(pa)); printf("size short: %lu\n", sizeof(short)); |
sizeof-operaattorin kanssa voi käyttää joko muuttujan nimeä tai
tietotyypin nimeä. Ylläolevassa esimerkissä näkyy
molempia. Esimerkiksi allekirjoittaneen Macissä sizeof(a) palauttaa
2 (tavua), kuten odotettua, ja sizeof(pa) palauttaa 8 (tavua), koska
osoitteet ovat 64-bittisiä. printf-muotuilumääreenä käytetään %lu,
koska sizeof palauttaa unsigned long - tyyppisen arvon (tai ei ihan,
asiasta seuraavassa enemmän).
Uusien tietotyyppien määrittely
Jotkut tietotyypit saattavat olla pitkiä kirjoittaa ja siksi hankalia käyttää. Lisäksi joskus halutaan ohjelmakoodin itsessään dokumentoivan, että tietyt muuttujat esittävät esimerkiksi lämpötilaa, vaikka esimerkiksi normaali float - tyyppi riittäisi siihen varsin hyvin.
typedef - määreellä voidaan määritellä uusia tietotyyppejä vanhojen pohjalta. Alla esimerkki siitä, kuinka tätä käytetään:
1 2 3 | typedef unsigned long mySize; long b; mySize a = sizeof(b); |
Tässä halutaan kertoa, että meillä on erikseen mySize - tietotyyppi, jolla ilmaistaan muuttujien kokoa. Itse asiassa C:n standardikirjastoissa määritellään tyyppi size_t tätä tarkoitusta varten. Tarkalleen ottaen sizeof palauttaakin size_t - tyyppisen arvon. Tiedämme että se vastaa useimmiten unsigned long - tyyppiä, mutta ei välttämättä.
Muuttumattomat parametrit ja muuttujat
Muuttujia ja funktioiden parametreja voidaan määritellä muuttumattomiksi. Tällaisia muuttujia ei voi muokata, vaan niiden arvon voi vain lukea. Tähän käytetään const - määrettä. Kun osoittimen yhteydessä annetaan const - määre, osoittimen osoittamaa arvoa ei voi muokata, vaan sen voi pelkästään lukea.
const - määre on hyödyllinen rajapintojen dokumentoimiseen ja niiden virheellisen käytön estämiseen. Huolellinen ja oikea const - määreen käyttö auttaa välttämään virheitä, ja on hyödyllinen varsinkin isoissa ohjelmitoissa, joita tyypillisesti on kehittämässä useita ihmisiä.
Alla esimerkki const - tyyppisen parametrin (virheellisestä) käytöstä funktiossa, joka yrittää muokata const-parametria.
1 2 3 4 5 6 | void a_func(const int *param) { int a = *param; a = a + 1; /* ok, koska alkuperäistä param:ia ei muuteta */ *param = *param + 1; /* EI onnistu, koska param:ia muutetaan */ } |
Ylläolevassa funktiossa param - parametri on muuttumaton. Siksi rivi 5 aiheuttaa kääntäjävirheen. Tällä tavoin saadaan kääntäjä suojelemaan ohjelmoijaa parametrin virheelliseltä käytöltä.
Seuraavassa esimerkki const-määreen käytöstä muuttujan määrittelyn yhteydessä. maxSize muuttuja on käytännössä vakio, jolla on sama arvo koko ohjelman ajan. Tämäkin on hyödyllinen ominaisuus koodin selkeyttämiseksi ja virheiden välttämiseksi: sen sijaan, että lukua 10 käytettäisiin useassa kohtaa koodia, voidaan käyttää vakiomuuttujaa. Jos päätämme kasvattaa vakiota esimerkiksi 20:een, muutos tarvitsee tehdä vain yhdessä paikassa ohjelmaa.
1 2 3 4 5 6 7 8 9 | const size_t maxSize = 10; /* globaali muuttuja, näkyy kaikkialla */ int main(void) { int i; for (i = 0; i < maxSize; i++) { /* do something */ } } |
C:ssä on mahdollisuus määritellä globaaleja muuttujia, kuten yllä. Ne näkyvät kaikissa funktioissa. Globaaleiden muuttujien runsas käyttö sotkee hyvää ohjelmarakennetta ja vaikeuttaa suurempien ohjelmien lukemista, joten niitä tulisi välttää aina kun mahdollista. Joskus globaaleja muuttujia kuitenkin joutuu käyttämään, tai niitä näkee vastaan tulevassa ohjelmakoodissa.
Paikalliset staattiset muuttujat
Kun funktiota kutsutaan, sen paikalliset muuttujat ovat normaalisti voimassa vain sen ajan kun funktiota suoritetaan. Kun funktiosta poistutaan, muuttujat vapautetaan ja niissä säilytetty tieto menetetään. Paikallinen muuttuja voidaan kuitenkin määritellä staattiseksi static - määreellä. Tällöin muuttujan tila säilyy ohjelman koko suoritusajan: kun funktiota kutsutaan uudestaan, staattisen muuttajan arvo on se, miksi se jäi funktion edellisellä suorituskerralla.
Käytännössä tätä mekanismia näkee käytettävän kohtuullisen harvoin, mutta alla esimerkki sen toiminnasta:
1 2 3 4 5 6 7 8 9 10 11 12 13 | #include <stdio.h> int tuplaa(void) { static int arvo = 1; arvo *= 2; return arvo; } int main(void) { for (int i = 0; i < 10; i++) { printf("Nyt: %d\n", tuplaa()); } } |
Funktio siis alustaa muuttujan vain ensimmäisellä kutsukerralla, ja kullakin kierroksella funktion palauttama arvo tuplaantuu. Viimeinen tulostettava arvo on 1024.
Staattiset funktiot ja globaalit muuttujat
Funktioiden ja globaalien muuttujien näkyvyyttä voi rajoittaa static - määreellä. Tämä on täysin erillinen toiminto kuin staattisilla paikallisilla muuttujilla, käytetty avainsana vain sattuu olemaan sama. Staattinen funktio (tai globaali muuttuja) näkyy vain siinä c-lähdetiedostossa, jossa se on määritelty. Suuremmat ohjelmistot, jotka koostuvat sadoista lähdetiedostoista (eli ohjelmamoduleista) hyödyntävät tätä ominaisuutta eritellääkseen ohjelmamodulin sisäisen toteutuksen (staattisilla funktioilla) ja ulkoiset rajapinnat (ei-staattisilla funktioilla).
Linux on esimerkki suuresta ohjelmistosta, joka koostuu suuresta määrästä C-kielisiä lähdetiedostoja. Siellä esimerkiksi tiedostossa tcp_input.c on funktio
1 2 3 4 | static void tcp_sndbuf_expand(struct sock *sk) { /* koodia*/ } |
jota voi käyttää vain tcp_input.c:n toisista funktioista. Näin kehittäjät voivat ohjata sitä, mitkä funktiot ovat muiden ohjelmamodulien käytössä, ja mitkä ovat "piilossa". Tarkoitus on jälleen ennaltaehkäistä ohjelmoijan virheitä ja välttää huonoa ohjelmistosuunnittelua. Useimpien ohjelmistojen elinkaari on nimittäin yllättävän pitkä.
Laskujärjestys
Operaattoreiden keskinäisen suoritusjärjestyksen ymmärtäminen on tärkeää, kun kirjoitetaan ja luetaan monimutkaisempia lausekkeita. Monet hankalasti löytyvät ohjelmavirheet liittyvät siihen, että esimerkiksi osoittimiin liittyvien operaattoreiden suoritusjärjestys ei ole ollut ohjelmoijalle selvillä, ja lausekkeella on tällöin aivan toisenlainen lopputulos mikä oli tarkoitus.
Taulukko operaattoreiden keskinäisestä laskujärjestyksestä löytyy esimerkiksi K&R - kirjan sivulta 53, tai erinäisiltä verkkosivuilta. Alla lyhyt (ja ei täysin kattava) yhteenveto tärkeimmistä operaattoreista.
(),[],->,.++,--,*(osoitin) ,&(osoite) ,(TYPE)(tyyppimuunnos) ,sizeof(arvioidaan oikealta vasemmalle))*,/,%(aritmeettiset operaattorit)+,-(aritmeettiset operaattorit)<,<=,>,>===,!=&&(looginen JA)||(looginen TAI)
Useimmiten samantasoiset operaattorit arvioidaan vasemmalta oikealle, mutta tason 2 operaattorit päinvastaiseen suuntaan, oikealta vasemmalle.
Yllä oleva taulukko selittää miksi sulkeita tarvitaan esimerkiksi silloin kun käsitellään taulukkoa viittausoperaattorin avulla, jotta ohjelma toimisi kuten halutaan. Esimerkiksi tämä ohjelma:
1 2 3 | int arr[10]; int b; b = *(arr + 2); |
hakee taulukon arr kolmannen alkion, kun taas tämä:
1 2 3 | int arr[10]; int b; b = *arr + 2; |
kasvattaa taulukon arr ensimmäistä alkiota kahdella. Jälkimmäisessä siis vain sulkeet oli otettu pois. Mikäli olet epävarma laskujärjestyksen suhteen, on hyvä muistaa että ylimääräinen (ja tavallaan "turha") sulkeiden käyttö ei riko ohjelmaa. Monimutkaisia lausekkeita voi myös palastella pienempiin osiin useammaksi lauseeksi apumuuttujia käyttämällä.
C ei määrittele operaattoreiden käyttämien parametrien keskinäistä
laskujärjestystä. Jos meillä on esimerkiksi lause int val = funcA() +
funcB();, emme tiedä kumpi funktioista kutsutaan ensin, ja eri
ympäristöissä funktioiden keskinäinen suoritusjärjestys voi olla
eri. Tämä on hyvä pitää mielessä ohjelmaa suunnitellessa.
Funktioita merkkijonoille
C:n standardikirjastossa on funktioita jotka helpottavat merkkijonojen
käsittelyä. Merkkijonofunktiot on määritelty
otsakkeessa <string.h>, eli se tulisi sisällyttää #include -
direktiivillä ohjelman alkuun, mikäli haluat käyttää näitä funktioita.
Funktioiden tarkat kuvaukset löytyvät Unix-manuaalisivuilta, joihin
pääset käsiksi man - komennolla komentoriviltä, tai verkon kautta
täältä.
Seuraavassa muutama hyödyllinen fuktio.
-
strlen palauttaa ennetun merkkijonon pituuden. Funktion tarkka määritelmä on
size_t strlen(const char *s), eli se saa parametrikseen osoittimen merkkijonoon ja palauttaa size_t - tyyppisen arvon. size_t:hän oli kirjastossa määritelty lisätietotyyppi, jota käytetään kokojen ilmaisemiseen, kuten myös sizeof - operaattorin yhteydessä. -
strcmp vertailee kahta merkkijonoa. Funktion tarkka muoto on
int strcmp(const char *s1, const char *s2). Funktio palauttaa 0, mikäli merkkijonot ovat samat, negatiivisen arvon mikäli s1 on ennen s2:ta aakkosjärjestyksessä, tai positiivisen arvom mikäli s1 on s2:n jälkeen aakkosjärjestyksessä. Funktion avulla voi siis myös järjestellä merkkijonoja. -
strcpy ja strncpy kopioivat merkkijonon. Funktioiden tarkka muoto on
char *strcpy(char *dst, const char *src)taichar *strncpy(char *dst, const char *src, size_t n), jossa src:n osoittama merkkijono kopioidaan dst:n osoittamaan paikkaan. Ohjelmoijan täytyy pitää huolta, että kohdeosoitteessa on varattu riittävästi tilaa merkkijonon tallettamiseen. Jälkimmäisessä funktiossa määritellään lisäksi, että funktio kopioi korkeintaan n merkkiä. Mikäli alkuperäinen merkkijono oli tätä pitempi, nollamerkki jää kopioimatta, mikä on hyvä huomioida ohjelmassa. Funktiot palauttavat osoitteen kohdemerkkijonoon. -
strcat ja strncat lisäävät yhden merkkijonon toisen perään. Tarkka muoto on
char *strcat(char *s1, const char *s2)taichar *strncat(char *s1, const char *s2, size_t n), jossa s2:n osoittama merkkijono lisätään s1:en perään. Jälleen ohjelmoijan tulee pitää huolta että kohteessa on varattuna riittävästi tilaa. Jälkimmäisessä versiossa n - parametrillä voidaan määrätä enimmäismäärän siirrettäville merkeille. -
strchr hakee annetun merkin merkkijonosta ja palauttaa osoittimen kyseiseen kohtaan. Tarkka muoto on
char *strchr(const char *s, int c), jossa c on etsittävä merkki, ja s on merkkijono josta etsitään. Mikäli kyseistä merkkiä ei löydy, funktio palauttaa arvon NULL. -
strstr hakee yhtä (lyhyempää) merkkijonoa toisen merkkijonon sisältä. Tarkka muoto on
char *strstr(const char *s1, const char *s2), jossa s2 on etsittävä merkkijono, ja s1 on se merkkijono jonka sisältä etsitään. Funktio palauttaa osoittimen kohtaan josta etsittävä merkkijono alkaa, tai NULL, jos merkkijonoa ei löytynyt.
Alla esimerkki, jossa ylläolevia funktioita käytetään.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <stdio.h> #include <string.h> int main(void) { char buffer[40]; char *strings[] = { "Paasikivi", "Kekkonen", "Koivisto", "Ahtisaari", "Halonen" }; int left, i; strcpy(buffer, strings[0]); left = sizeof(buffer) - strlen(strings[0]); i = 1; while (left > 0 && i < 5) { strncat(buffer, strings[i], left - 1); left = left - strlen(strings[i]); i++; } printf("buffer: %s, length: %lu\n", buffer, strlen(buffer)); } |
Rivillä 6 varataan muuttuja buffer, joka sisältää tilaa 40 merkille (joista viimeisen pitää olla 0-merkki). strings on taulukko merkkijonoja, joista kukin on varattu luettavalta muistialueelta, eli niiden sisältöä ei voi muuttaa. Toisinsanoen kukin taulukon alkio on osoitin muistialueelle, jossa nämä vakioidut merkkijonot sijaitsevat.
Rivi 11 kopioi ensimmäisen merkkijonon ("Paasikivi") buffer -
muuttujaan. strings[0]:n tietotyyppi on char *, ja
merkkitaulukko buffer voidaan käyttää osoitinparametrin paikalla,
jolloin osoitin viittaa tämän alkuun.
Muuttujassa left pidetään kirjaa siitä, kuinka monta merkkiä muistialueelle vielä mahtuu. Sen alkuperäinen koko on siis buffer-taulukon koko, ja siitä vähennetään kopioidun merkkijonon pituus. while - silmukassa sitten lisätään buffer-merkkijonon perään aina kulloinenkin taulukon merkkijonoalkio, mutta samalla varotaan kirjoittamasta puskurin yli käyttämällä strncat - funktiota.
Loppujen lopuksi rivillä 19 tulostetaan saatu buffer - merkkijono. Seuraavaa pitäisi tulostua:
buffer: PaasikiviKekkonenKoivistoAhtisaariHalon, length: 39
Viimeinen presidenttinimi ei mahtunut puskuriin lainkaan, ja Halosestakin jäi vähän puuttumaan, mutta left - muuttujan avulla varmistimme että emme kirjoittaneet yli varatun muistialueen, mikä olisi sotkenut ohjelman toimintaa jollain tavalla.
Task 06_strbasic_2: Laske merkkijonot (1 pts)
Tavoite: Harjoitellaan merkkijonofunktioiden käyttöä (harjoituksen voi myös tehdä ilman niitä).
Toteuta funktio int count_substr(const char *str, const char *sub)
joka laskee kuinka monta kertaa merkkijono sub esiintyy
merkkijonossa str, ja palauttaa lukumäärän
paluuarvonaan. Esimerkiksi kun kutsutaan count_substr("one two one
twotwo three", "two"), funktion tulisi palauttaa 3, koska "two"
esiintyy ensimmäisessä merkkijonossa 3 kertaa. Huomaa että
esimerkiksi välilyönneillä ei ole mitään erikoisvirkaa merkkijonossa,
ne ovat merkkejä siinä missä muutkin.
Vihje: Funktio strstr saattaa olla avuksi. Voit myös käsitellä merkkijonon osia, kun siirrät (esimerkiksi funktiolle annettavan) osoittimen haluttuun kohtaan keskelle merkkijonoa. Tällöin esimerkiksi kutsuttu merkkijonofunktio ei käsittele osoitinta edeltäviä merkkejä.
Task 07_altstring: Uusi merkkijono (4 pts)
Tavoite: Kuinka merkkijonofunktiot on toteutettu? Tämä harjoitus saattaa valottaa asiaa.
Tässä tehtävässä luomme uudenlaisen merkkijonon, joka ei lopukkaan '\0' - merkkiin, kuten normaalit merkkijonot, vaan loppumerkkinä käytetäänkin risuaitaa ('#'). Tästä johtuen joudumme toteuttamaan perinteiset merkkijonofunktiot uudestaan.
Huomaa, että
a) Tulosta merkkijono
Toteuta funktio void es_print(const char *s) joka tulostaa annetun
uudentyyppisen merkkijonon ruudulle. Merkkijono loppuu siis '#' -
merkkiin, jota ei pidä tulostaa. Esimerkiksi seuraavanlainen
merkkijono:
1 | char *str = "Auto ajoi#kilparataa"; |
tulostuu näin:
Auto ajoi
b) Merkkijonon pituus
Toteuta funktio unsigned int es_length(const char *s) joka palauttaa
merkkijonon s merkkien lukumäärän. Merkkijonon päättävää risuaitaa
ei lasketa mukaan.
c) Merkkijonon kopiointi
Toteuta funktio int es_copy(char *dst, const char *src) joka kopioi
merkkijonon src paikkaan dst. Funktio palauttaa kopioitujen
merkkien lukumäärän, poislukien merkkijonon päättävä '#' -
merkki. Funktion tulee kopioida lähde merkkijono vain ensimmäiseen
'#' - merkkiin asti, ja kopioinnin jälkeen myös dst:een kopioidun
kohdemerkkijonon tulee päättyä risuaitaan. Voit käyttää aiemmin
toteuttamaasi es_print - funktiota testaamaan toimiiko kopiointi
oikein.
d) Merkkijonon pilkkominen
Toteuta funktio char *es_token(char *s, char c), joka katkaisee
merkkijonon s kun ensimmäinen parametrin c esittämä merkki tulee
vastaan. Kyseinen kohta merkkijonosta muutetaan siis lopetusmerkiksi,
eli risuaidaksi. Funktio palauttaa osoittimen korvattua merkkia
seuraavaan merkkiin, mistä alkuperäinen merkkijono jatkuisi. Näin
ollen, kun funktiota kutsutaan useaan kertaan, käyttäen paluuarvoa
aina uudestaan parametrina osoittamaan jäljellä olevan merkkijonon
alkuun, voidaan alkuperäinen merkkijono pilkkoa useaksi osaksi.
Mikäli c:n osoittamaa merkkiä ei löydy, tulee funktion palauttaa
NULL (joka määritelty <stddef.h> - otsakkeessa). Huomaa myös että
funktio muokkaa alkuperäistä merkkijonoa, eikä siitä esimerkiksi
oteta kopiota.
Esimerkiksi kun kutsutaan es_token(str, ',') tällaiselle merkkijonolle:
1 | char *str = "aaa,bbb,ccc#ddd,eee"; |
merkkijono muuttuu seuraavanlaiseksi:
"aaa#bbb,ccc#ddd,eee"
ja funktio palauttaa osoittimen kohtaan, josta "bbb" alkaa. Huomaa myös että '#'-merkin jälkeisiä pilkkumerkkejä ei vaihdeta, koska funktio lopettaa '#'-merkkiin (ellei parametriksi anneta osoitinta kohtaan, josta "ddd" alkaa).
Task 08_korso: Korsoraattori (1 pts)
Tavoite: Lisää tuntumaa merkkijonojen pyörittelyyn. Tämä harjoitus on tribuutti legendaariselle Korsoraattori-palvelulle.
Toteuta funktio void korsoroi(char *dest, const char *src), joka
korsoroi annetun merkkijonon src ja kirjoittaa muutetun merkkijonon
osoitteeseen dest. Merkkijono muutetaan korsoksi seuraavalla tavalla:
- Jokainen "ks" alkuperäisessä merkkijonossa tulee muuttaa "x":ksi kohdemerkkijonossa.
- Jokainen "ts" alkuperäisessä merkkijonossa tulee muuttaa "z":ksi kohdemerkkijonossa.
- Joka kolmannen alkuperäisessä merkkijonossa olevan sanan jälkeen tulee lisätä ylimääräinen sana "niinku" kohdemerkkijonoon.
- Joka neljännen alkuperäisessä merkkijonossa olevan sanan jälkeen tulee lisätä ylimääräinen sana "totanoin" kohdemerkkijonoon.
Sanaeroittimena käytetään välilyöntiä (' '). Sinun ei tarvitse lisätä mitään viimeisen alkuperäisen sanan jälkeen, ja voit olettaa että kohdemerkkijonossa dest on varattuna riittävästi tilaa. Voit lisäksi olettaa että kaikki kirjaimet ovat pieniä kirjaimia.
Esimerkiksi merkkijonosta "yksi auto valui itsekseen ilman kuljettajaa mäkeä alas" tulee "yxi auto valui niinku izexeen totanoin ilman kuljettajaa niinku mäkeä alas".
Task 09_stringarray: Merkkijonotaulukko (2 pts)
Tavoite: Kurkistetaan taulukkoihin, joiden jäsenet ovat merkkijonoja (eli taulukot ovat käytännössä kaksiulotteisia)
Myös merkkijonoja voi käyttää taulukoissa. Koska merkkijono on merkeistä muodostuva taulukko, merkkijonotaulukko on taulukko merkkijonoja, joista kukin on taulukko merkkejä. Tässä tehtävässä käsitellään merkkijonotaulukkoa, jossa taulukon loppu ilmaistaan NULL-osoittimella.
a) Tulosta merkkijonotaulukko
Toteuta funktio void print_strarray(char *array[]), joka tulostaa
jokaisen merkkijonon taulukossa array omalle rivilleen (eli jokaisen
merkkijonon lopussa on rivinvaihto). Funktion parametrin esitysmuoto
saattaa näyttää uudenlaiselta: Parametri array esittää taulukkoa,
jonka kukin alkio on tyyppiä char *. Käytät siis kutakin taulukon
alkiota kuten merkkijonoa, esimerkiksi osana lausekkeita tai
printf-funktion parametrinä. Muista että taulukon loppu merkitään
NULL-osoittimella.
b) Muunna merkkijono taulukoksi
Toteuta funktio void str_to_strarray(char* string, char** arr) joka
muuntaa parametrinaan saamansa merkkijonon string taulukoksi
merkkijonoja (muuttujaan arr). Alkuperäinen merkkijono voi sisältää
useita välilyönnillä erotettuja sanoja, ja funktion tehtävänä jakaa
merkkijono siten, että kukin välilyönnillä erotettu sana muodostaa
oman alkionsa taulukossa. Muista erottelun jälkeen kunkin merkkijonon
tulee päättyä nollamerkkiin, sekä lisäksi taulukon tulee päättyä
NULL-osoittimeen.
Kaksiulotteisia taulukoita ei ole vielä käsitelty, mutta kun arr[i]
esittää merkkijonoa edellä kuvatun kaltaisessa taulukossa, pääset
käsiksi kyseisen merkkijonon j:nteen merkkiin merkinnällä arr[i][j],
joko merkin kirjoittamista tai lukemista varten.